| 2.4 Designing Rule Bases |
| Home | Business Rules | Rule Based Systems | Rule Engines | Semantic Web | Links | Under the Hood |
|
Traditional Rule Based Systems as a Starting Point
|
So
far, the definition of a "rule based system" has remained
obscure. One reason is that current definitions of rule based
system depend almost entirely on "expert systems", which are
system that mimic the reasoning of human expert in solving a knowledge
intensive problem, such as diagnosing a fault in an automobile
or nuclear plant. On the other hand, traditional definitions of rule based systems are probably a good starting point for where ever the 'Semantic Web' may lead. From this perspective, it may be easier to describe how they work than try to define what they are. |
More ...
|
|
Data, Conditions and Rules
Innate Facts versus Derived Facts Conditions as the Result of Tests
|
The
following is a very quick and a simplified picture of a rule
base. It consists of three components - data, conditions and rules.
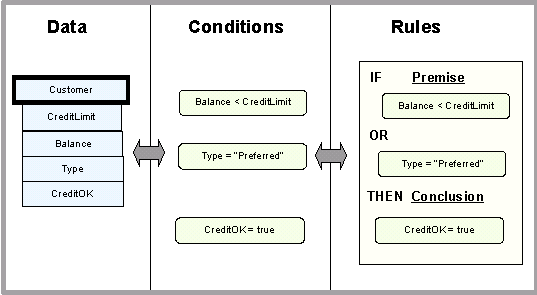
Data associates the value of characteristics with a thing ( characteristics are often called attributes ). Data can be innate facts about a thing, such as a customer have a type or status or derived facts about a thing or class of things, like customers who have good credit. Conditions perform tests of the values of a characteristics to determine if something is of interest, perhaps the correct classification of something or whether an event has taken place. For instance, if the outstanding balance for a customer exceeded the credit limit. The value of the data elements Customer.Balance and CreditLimit would be tested in the condition "Cusomter.Balance > Credit Limit". Once the condition was determined that the customer is no longer considered a good credit risk, it could trigger a process to collect the amount due form the customer. The evaluation of the condition itself results in a "truth value" of true or false, or else it remains unknown. Rules have two part - a premise and a conclusion, the the form of IF the premise THEN a conclusion. The rule tests the logical expression in the premise, and, if the expression evaluates to true, it then asserts that a fact about a thing or a class of things is true. This may sound a bit convoluted at the moment, but it gets worse. |
|
|
Conditions as the Building Blocks of Inference
Value by Assignment
Value by Assertion
Capturing Inconsistencies and Contradictions
What-if Inferences
|
Logical expressions are combinations of conditions within a construction of ANDs and ORs. For instance, in the following diagram, if either of the conditions "Customer.Balance <CreditLimit" OR "Customer Type is Preferred" is true, then rule asserts that "Customer Credit OK = true" is true. Note that rules do not interact directly with data, but only with conditions either singly or within an AND/OR construction of some sort.
The diagram above shows the basic parts and interactions between them. It is not clear in the diagram exactly how the data value CreditOK is getting set to the value true or false. Why is there a separate condition "Customer.CreditOK = true", when it would be much easier just to set the value of the data element "Customer.CreditOK to the value true ? One source of confusion is that there are two ways for a rule to set new values. The first way can be called 'value by assignment', where the data value CreditOK is being set directly to the value true or false. The second is 'value by assertion', where value of the condition "CreditOK = true" is asserted to be true. The assertion that "CreditOK = true" does not not in itself assign a value of true to the data value CreditOK, rather the condition acts like a constraint upon the data value, saying it must be the value specified by the condition. This may be odd at first, but consider the case of a three-legged cat, where the data element "cat.legs" is equal to 3. The observed characteristic is at variance with the universal assertion that "All cats have 4 legs". The fact that a particular cat has a different number of legs does not invalidate the universal rule about the proper number of legs for a cat. In fact, it is an interesting discrepancy and one can readily see the usefulness of this distinction in capturing inconsistencies between innate and derived characteristics of some type of thing, cats in this case. What is more, 'value by assertion' can also capture contradictions between derived facts, that is where one rule is saying Customer.CreditOK is true and another rule is saying that it is false. This can produce a very revealing picture of a rule base, especially if one is comparing or merging rules from different sources, as might be expected of a knowledge sharing environment in a Semantic Web. Usually both 'value by assignment' and 'value by assertion' are at work within a rule base. When an inconsistency arises such as a three-legged cat or an outright contradiction such as CreditOK is both true and false, the path of inference can split a that point and two lines of inference can travel down each branch of the path to find further contradictions. In fact, many high-powered rule engines for business applications do not perform 'what if' inferences of this sort. Most business applications have little need to capture inconsistencies and contradictions in their normal functioning. Analysts and designers spent too much time eliminating ambiguities in the rule base to allow them into their transaction systems. This may not be true of Semantic Web applications. |
|
| Classification
of Rules
Function, Structure and Behavior Again
|
There
are several
ways to recognize and create useful classifications of rules. A given
rule
will have a classifier for each of its function, structure and behavior, and
possibly several behavior classifications. Returning the FSB criteria, we can ask: What is the rule's function ? What does the rule accomplish ? What is its structure ? How is a rule formed ? What is its behavior ? How does a rule act ? The structural and functional classifications are more appropriate for a relatively simple business rule or semantic web applications, based on information derived from a standard database and rules repository. Behavioral classification of rules cans be a very complex topic and is often encountered more in the implementation and debugging of rules rather than their specification. |
|
|
Functional Classification
|
Functional classifications are the easiest to use and understand. Often, rules can be associated with a single subject, typically a business process such as Order Processing or Customer Credit. Consequently, they take the names of 'Order Process Rules" or 'Customer Credit Rules'. Even large business rules systems will use functional classifications as the primary determinate or rule 'type'. The hierarchy of rule types may correspond to a structure as simple as top-down decomposition of business functions. For sufficiently well-ordered business problems, this approach is often good enough, so long as there are few interactions between the different types of rules. In more knowledge intensive applications, such as diagnosing machine failures or in complex planning or routing problems, multiple interactions between the various types of rules makes functional categories less useful as the sole indicator of rule types. For example, when determining the ship date for a product that is out of stock, the 'Customer Order Rules' may need to invoke a complex set of inventory restocking rules to calculate a definite ship date for the backordered product, particularly in a case where a large surge in demand for a product might cause a recalculation of the reorder quality. In this case, multiple dependencies would work to cause a flurry of interaction between the different types of rules, requiring careful design of the rule base in order to eliminate the likelihood anomalous results. Nevertheless, functional categorization often remains the default classification scheme for rules in ordinary discourse between people, even in situations where the rules fail to cluster themselves into neatly divided functional categories. |
|
|
Structural Classification
Three Types of Rule Structures Logic Rules, Definitions and Constraints
|
Structural classification
of rules has the advantage of classifying rules precisely and unambiguously.
However,
the structural classification of a rule will not describe
important business aspects of that rule, unlike functional classification.
The primary distinction of structural
classification is the ability to separate the "wheat from chaff" and provide
some clues about the best way to implement a rule.
Structural classification yields exactly three types of rules: logic rules, definitions and constraints. The following sections describe the three structural types in detail. |
|
|
Logic Rules Rule Structures with Both Conditions and Consequences |
Logic rules are business
rules with a classical IF/THEN structure that people commonly
understand. They are also called 'policies' or ( confusingly
) 'business rules'. If the conditions of the premise are met,
then the conclusion about relationships between data entities must be
true. The value of some data element is set according to the
conclusion of the rule.
From a structural standpoint, a "logic rule" in the restricted sense has a distinct test condition in the IF clause and a conclusion that changes something in the THEN clause For example:
Only a logic rule has a clearly recognizable IF condition and a THEN conclusion. The conclusion changes the value of something in the system. In this restricted sense of the term "rules", entities such entities as database constraints and unconditional computations are distinctly not rules. Note that the use of the term "logic rule" in this context may be at variance with more restricted definitions of the term "rule". The meaning of "logic rule" is more restricted than "business rule". Sometimes methodologies use the term "policy" rather than "logic rule" in this context. We use the term "policy" in an even less constrained sense than "business rule". The term "policy" is used in the sense of the sense of a "corporate policy" that any business manager or customer would recognize and understand. A "business rule" is restricted to rules owned and expressed by business people. A "logic rule" is more restricted still. It is a rule with a certain type of structure. This has implications for the analysis and implementation of the rule. |
|
|
Definitions |
A
"definition" is
essentially a THEN conclusion with no IF condition. It is
unconditional, except for trivial validations of variable bindings and
divide by zero conditions.
A definition constructs values from other values. Values may be the result of the application of previous definitions, or they may be the result of executing the conclusions of logic rules. Example: IF Anything ( Always true ) THEN ValueC = (X + Y ) / Z ( Assign or compute a value ) Definitions often comprise the majority of rule entities in most applications. Definitions are unconditional so they are often implemented as procedural code or logical view of the database. A simple definition might be implemented in computer code. An accumulation of values such as "deductible accumulations" might be implemented as a SQL query. In contrast to unconditional definitions, complex and volatile logic rules are often implemented in a more flexible manner with a rule engine with inference capabilities. Logic rules can generate complex and unpredictable system behaviors and are also more likely to change over the course of time. |
|
|
Constraints Rule Structures Conditions but no Consequences |
Constraints are essentially IF conditions with no THEN conclusion. A constraint describes a violation of a relationship between data entities. There is no change of value within the data. It is information about the data, that is meta-data. A constraint will often trigger an exception, such sending a message to someone to make an inquiry or order more parts. An exception is actually a business process rather than a business rule per-se. A business process can be viewed as a specialized form of rule. In essence, the entry condition to the process is the IF part of the rule that recognized the event or exception. In any case, there is no change in the value or state of the any underlying business entity. In our terminology, a "rule" such as "every claim must have a member number" becomes a constraint rather than a logic rule. Example:
The exception referred to in the example is usually an error process. The process will either prompt the user that there is an error condition or log the error condition to an error file. The exception may alter or interrupt the flow of process steps or of the rule engine itself. Database relations such as 'every order must have a customer' often comprise a large proportion of constraints and are usually implemented within a database. Complex or localized constraints may be implemented as logic rules that cause the rule engine to trigger a response from the database. Constraints raise an exception and prevent a change rather than causing a change. Frequently they may cause an irreversible 'side-effect', such as writing a message to an error log or asking the user to do something. In any case, the natural flow of inference is interrupted while some process runs outside of the rule engine either to flag or rectify the problem or to stop the rule engine altogether. Constraints can be a show stopper. |
|
|
Behavioral
Classification of Rules
Interactions Between Rules
Interactions Between Data Values
Defaulting Logic
|
Behavioral
classification and rule behavior in general can be a very complex
topic. Rule behavior can arise either from interactions between
rules or between the values of the data being used to test conditions
within a rule. Often, the interactions can effect the answer given
by the rule base, either by being over-determined ( more than one answer
) or under-determined ( no answer at all ).
For example, there are situations where a health insurance claim form can be used for a single medical procedure on a single day or for a series of medical procedures over the course of several days. The situation where a single source of data can represent either one thing or several things is always a prime source of confusion, often generating overly complex business rules. In this case, it might require a significant amount of logic to determine the start and end dates for the claim as a whole. If there are a single set of dates at the top of the form and there are also several procedures performed over the course of several days, then the start and end dates of the form would need to reconciled with the dates of the first and last procedures, no matter what the dates are used at the top of the form. Sometimes, there are no dates at the top of the form, or else there is an end date and no start date, etc. Deciding which data value defaults to what can get quite involved, even in a relatively simple example. The complexities of defaults for data values is often an inescapable part of rule base design. For instance, a defaulting rule might look like:
Notice that the same data element ( ValueA ) appears in both the premise and the conclusion. This a guarantee of strange rule behavior ( for reasons which will be made clear in the "Rule Engines" section ). While some rule engines are designed to take care of this situation, what actually happens with any given set of values is not intuitively apparent. It will depend on which rule the rule engine selects to evaluate first and what it does with the rule afterward. To make matter worse, what if there were two perfectly legal and well-formed rules saying:
What happens here ? Does the value just bounce back and forth between "123" and "456" ? In the context of a simple implementation of a rule base, it is highly desirable to take care of default values separately from logic rules, in what is called 'deterministic' rules. The basic idea is, if all other rules fail to produce a value, use the default value. |
|
|
Action Rules as Behaviors
Workflows
Eliminating Rule Behavior with Workflows
|
In other definition schemes, 'behavior rules' or 'action rules' are rules that do things like update a database or print a report, something that can not be undone, at least not directly and easily. In this scheme, action rules are considered to be workflows, which live a sort of semi-autonomous existence on the same level as rules. Set of conditions within rules initiate workflows of some sort: something concrete must be done, or not done in the case of constraints. However, the thing being done are generally outside the knowledge and functioning of the rule engine itself. Workflows are the natural purview of a workflow manager rather than a rules engine, although many rules engines have some level of workflow capabilities. Interactions between business rules and workflows can be quite complex and required special attention when designing a business process / business rule application. In fact, a major objective of this particular approach to rule base design is to eliminate rule behavior altogether, or al least as much as possible. Rule behavior can produce very complex interactions between rules - it can be very tricky to understand and control or even to detect at times. Ideally, the rules should "say what they mean and mean what they say" without reference to some external condition or factor outside the control of the rule engine. The use of workflows in place of action rules helps to isolate irreversible side-effects from the rule base. |
|
|
|